分布式ID生成器有哪些?
📌 分布式ID生成器有哪些?——架构设计与核心原理深度解析
📌 1️⃣ 问题背景
在分布式系统中,传统数据库自增ID已经无法满足高并发、多节点、多数据中心的业务需求。随着微服务架构的普及,系统需要一种全局唯一、趋势递增、高性能的ID生成方案。
典型问题包括:
- 数据库自增ID在分库分表后冲突
- 单点生成ID性能瓶颈
- 跨机房ID无法保证唯一性
- 排序与趋势性需求难以满足
⚠️ 结论:分布式ID本质是一致性 + 高性能 + 可扩展性之间的权衡问题。
🎯 2️⃣ 核心原理
分布式ID生成器的核心目标是:在不同节点之间生成不会冲突的唯一ID。
主流设计思想可以归纳为三类:
- 📌 中心化生成(数据库/Redis)
- 📌 号段模式(Segment模式)
- 📌 分布式算法(Snowflake等)
核心本质是:通过时间、机器ID、序列号等维度组合,构造一个64位或更长的整数。
💡 核心公式思想:
ID = 时间戳 + 机器ID + 序列号(或业务位)
📊 3️⃣ 数据结构分析
不同ID生成方案,本质上是对“long类型64位”的不同拆分方式。
以经典 Snowflake 为例:
- 1 bit:符号位(固定0)
- 41 bit:时间戳(毫秒级)
- 10 bit:机器ID(数据中心 + 节点)
- 12 bit:序列号(同毫秒内递增)
结构示意:
0 | 41-bit timestamp | 10-bit machine | 12-bit sequence
这种结构保证了:
- 📌 时间有序性
- 📌 高并发支持(每毫秒4096个ID)
- 📌 分布式唯一性
🚀 4️⃣ 算法分析
不同算法本质是不同工程权衡:
① 数据库自增
通过 MySQL 或 Oracle 的 auto_increment 实现。
缺点:单点瓶颈明显,不适合高并发。
② Redis INCR
利用 Redis 单线程原子性生成递增ID。
优点:性能高;缺点:依赖Redis持久化与高可用。
③ 雪花算法(Snowflake)
Twitter 提出,是目前最主流方案。
特点:无中心、趋势递增、高性能
④ 号段模式(Segment)
美团 Leaf 提出的优化方案,通过批量获取ID区间减少DB压力。
⚙️ 5️⃣ 执行流程
以 Snowflake 为例:
流程如下:
开始
↓
获取当前时间戳
↓
判断是否同一毫秒(维护一个全局变量)
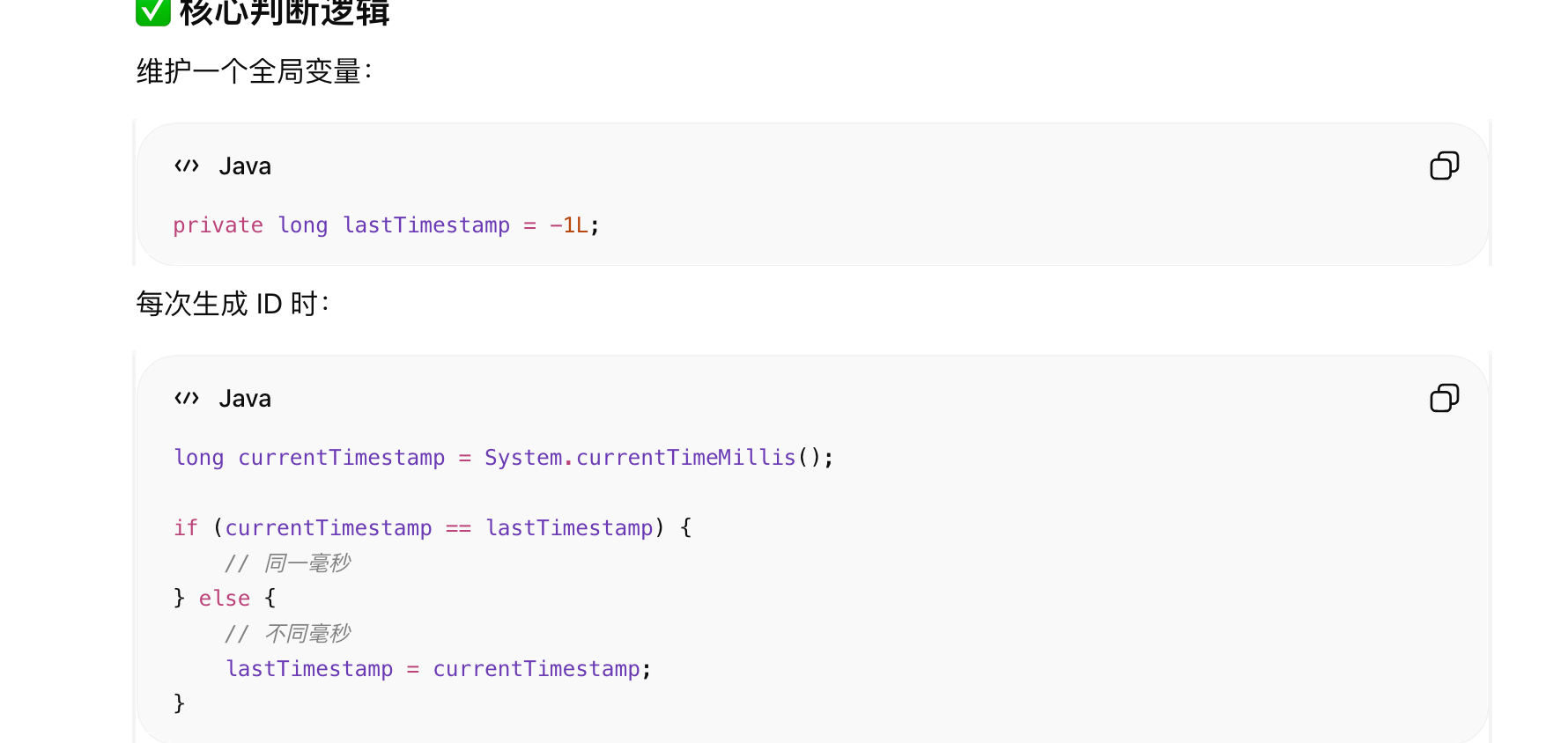
↓
是 → 序列号 +1
否 → 序列号重置为0
↓
拼接机器ID + 时间戳 + 序列号
↓
返回64位ID
结束
⚠️ 注意:如果同一毫秒序列号耗尽,需要自旋等待下一毫秒。
📦 6️⃣ 实际案例
在电商系统中,下单ID生成必须满足:
- 订单ID唯一
- 支持高并发秒杀
- 支持分库分表排序查询
采用 Snowflake 后:
QPS 可提升至百万级,同时保证 ID 趋势递增
美团 Leaf 使用号段模式:
- 数据库仅负责分配区间
- 应用本地生成ID
- 性能提升 10~100倍
⚖️ 7️⃣ 优缺点分析
📌 Snowflake
优点:
- 高性能
- 去中心化
- 趋势递增
缺点:
- 时间回拨问题
- 机器ID管理复杂
📌 号段模式
优点:
- 性能极高
- 数据库压力低
缺点:
- 实现复杂
- 可能浪费号段
📌 Redis方案
优点:
- 实现简单
缺点:
- 依赖中间件
❓ 8️⃣ 面试常见问题
- 💡 Snowflake为什么不需要中心节点?
- 💡 如何解决时间回拨问题?
- 💡 号段模式为什么比数据库自增快?
- 💡 分布式ID如何保证趋势递增?
- 💡 如何设计一个支持百万QPS的ID生成器?
⚠️ 面试重点:必须理解“时间 + 机器 + 序列号”的组合思想
🏁 9️⃣ 总结
分布式ID生成器是分布式系统的基础能力,其核心在于在性能、唯一性、趋势性之间找到平衡点。
不同方案适用于不同场景:
- Snowflake:适合互联网高并发系统
- 号段模式:适合超大规模订单系统
- Redis方案:适合轻量级业务
🚀 架构本质:没有最优方案,只有最适合业务的方案
相关文章
-
dubbo支持多种协议:
dubbo支持多种协议:
NEW个对象 2025-02-26
-
B树与B+树的区别
B树与B+树的区别
NEW个对象 2024-12-25
-
认证授权:OAuth2简介及四种授权模型详解
认证授权:OAuth2简介及四种授权模型详解
NEW个对象 2026-06-11
